全书模拟器的匹配机制是怎样的?如何使用?
- 家电指南
- 2025-05-25
- 33
- 更新:2025-05-09 19:53:41
随着数字化时代的到来,阅读方式也在不断演变。全书模拟器作为一种新型的数字阅读工具,给用户带来了便捷的阅读体验。本文将深入解析全书模拟器的匹配机制,并指导你如何有效地使用这一工具。
全书模拟器匹配机制解析
一、全书模拟器匹配机制基础
全书模拟器的匹配机制是模拟器智能识别和匹配书籍内容的关键所在。一般来说,模拟器会通过算法对文本进行处理,包括但不限于文字识别(OCR)、关键词提取、上下文理解等。核心算法通常包括机器学习技术,让模拟器随着使用次数的增加而提升其匹配的准确性和效率。
二、匹配机制的工作原理
全书模拟器通过以下步骤实现对书籍的匹配:
1.图像扫描:用户首先通过模拟器的扫描功能上传书籍页面的图片。
2.文字识别:模拟器运用OCR技术将图片中的文字转换成可编辑的文本格式。
3.文本处理:经过预处理的文本将通过自然语言处理技术,进行关键词提取和上下文理解。
4.智能匹配:根据提取的信息,模拟器通过内建数据库或互联网资源进行匹配查找。
5.呈现结果:最终用户将看到智能匹配后的书籍内容。

如何使用全书模拟器
一、了解基本操作流程
使用全书模拟器之前,了解其基本操作流程至关重要。通常包括以下步骤:
1.下载和安装:首先从官方网站或应用商店下载并安装全书模拟器。
2.打开应用:启动全书模拟器,并按照引导完成初步设置。
3.扫描书籍:利用模拟器提供的扫描功能,开始扫描你想模拟的书籍页面。
4.预览和编辑:查看扫描结果,并在必要时进行文字校对和编辑。
5.匹配和查看:模拟器自动匹配文本并显示结果,用户可以在此时选择查看或进行其他操作。
二、高级使用技巧
对于高级用户而言,以下技巧可以帮助更好地使用全书模拟器:
优化扫描环境:确保扫描光源均匀,避免产生阴影,以提高OCR的识别准确率。
利用快捷键:熟悉并运用全书模拟器的快捷键,可以有效提升使用效率。
定制匹配设置:根据个人喜好,可以调整匹配算法中的各种参数,以获得最佳匹配效果。
备份和导出:定期备份模拟数据,并在需要时导出,以避免数据丢失。

用户常见问题及解答
Q1:全书模拟器是否支持所有类型的书籍?
A1:大多数全书模拟器设计用于识别印刷文字,并不适用于手写体或图表密集的书籍。一些模拟器可能对特定语言或字体支持度不同。
Q2:OCR识别率不高怎么办?
A2:如果识别率不高,可以尝试提高扫描质量,或手动校正扫描错误。一些高级模拟器允许用户对OCR结果进行逐字校对。
Q3:全书模拟器匹配的数据安全吗?
A3:正规的全书模拟器会采用安全措施保护用户的隐私和数据安全,如加密存储和传输等。但使用时应仔细阅读隐私政策,确保个人信息的安全。

综上所述
全书模拟器通过其高效的匹配机制,大大提升了用户的数字阅读体验。了解其工作原理和正确使用方法后,可以有效地利用这一工具。无论是优化操作流程还是掌握高级技巧,全书模拟器都能让你在数字化阅读的世界中更加得心应手。记得在使用过程中注意隐私保护和数据安全,确保拥有一个愉快和高效的阅读体验。


热门文章

平板水冷散热器维修方法是什么?维修难度如何?
2025-07-11
苹果十快速充电器怎么用?使用方法和注意事项是什么?
2025-07-10
美颜相机如何搭配抖音音乐?使用方法是什么?
2025-06-25
雷神驱动独立显卡的使用方法是什么?
2025-06-25
苹果充电器包装盒的正确打包方法是什么?
2025-06-25
天选4无法使用手机充电器充电的原因是什么?
2025-06-26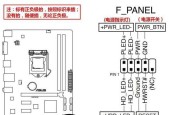
主板程序如何编写?编写主板程序的步骤是什么?
2025-06-27
三星手机双卡切换通话方法是什么?操作步骤详细吗?
2025-07-17